Benefits of Data Access Encapsulation
We all know that achieving a good Separation of Concerns is good, because it increases the maintainability and it reduces the cost of changing our code. This pays off big time in long running projects, with large code bases where changing code is a big part of the coding activity

We all know that achieving a good Separation of Concerns is good, because it increases the maintainability and it reduces the cost of changing our code. This pays off big time in long running projects, with large code bases where changing code is a big part of the coding activity and where the predictability of the effects of our changes is very important.
A while ago I have written a post that shows how to achieve a good separation of the Data Access Concern, even when using an ORM like Entity Framework. I've outlined there that just using the EF for the data access is not enough because it does not give consistency. I have also presented the iQuarc Data Access library (available on GitHub and on NuGet.org), which implements the Repository and Unit of Work patterns making a good encapsulation of the data access concerns and creating consistent development patterns on how the data access will be used from the above layers in the entire code base. We've used this library in many projects we've started since then, and we've seen many benefits on the cost of adding technical features later, because of the well encapsulated data access. In this post I'm going to give some examples of them.
The context of these examples is the one of large projects where after a few months of developing business functionalities (lets say data entry screens) we need to add some technical functionalities (let's say auditing each query execution). Without a central place through which all queries' execution goes, we would need to go back thorough all of the Controllers and the Services and log the query execution. So the effort to consistently add such a technical feature depends on the size of the project (code) at the moment we add it. The more Controllers and Services we have, the more places we need to modify and test, so the more effort is needed. Even more, the effort/cost is not linear to size, because complexity is not linear to size and the complexity grows because we don't have a consistent way to doing data access. Below graphic shows this:
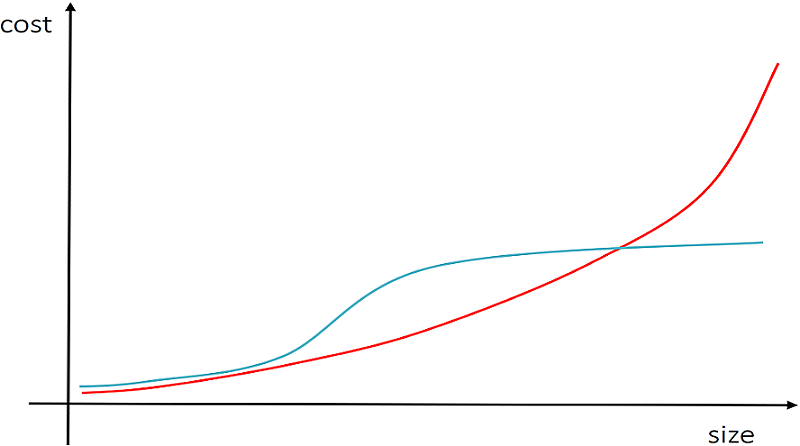
The red line represents the case where we need to go screen by screen and add the technical feature and the blue line represents the case where we have a well encapsulated data access implementation that allows such extensions. We see that in the second case the cost hardly grows by size, after we have such a data access implementation in place.
Now lets see the examples one by one. I'll list them here for an easier navigation. For some, I might write separate posts, so this one doesn't get way too long :)
- Write in an audit log when an entity was read, modified or deleted
- Data Audit
- Data Localization
- Multitenancy
- Authorization on data records
Write in an audit log when an entity was read, modified or deleted
Context: We need to write in an audit log the name of the user that has read, modified or deleted a Patient entity related data and the date and time when the action happened.
Without a centralized place through which all our queries and commands go, we would need to go through all our code where the Patient entity is added, modified or deleted, and make a call to the IAuditLog in a consistent way.
If we use the iQuarc Data Access library, we can create an entity interceptor for this by implementing the IEntityInterceptor<T> interface, and that would be all:
[Service(nameof(PatientAuditLogInterceptor), typeof(IEntityInterceptor<Patient>)]
class PatientAuditLogInterceptor : EntityInterceptor<Patient>
{
private readonly IAuditLog auditLog;
public PatientAuditLogInterceptor(IAuditLog auditLog)
{
this.auditLog = auditLog;
}
public void OnLoad(IEntityEntry<Patient> entry, IRepository repository)
{
User user = GetCurrentUser();
Patient patient = entry.Entity;
auditLog.Write(AuditType.Read, $"Patient data was read. Patient Name: {patient.Name}", user);
}
public void OnSave(IEntityEntry<Patient> entry, IUnitOfWork unitOfWork)
{
User user = GetCurrentUser();
Patient patient = entry.Entity;
if (entry.State == EntityEntryState.Added)
auditLog.Write(AuditType.Added, $"Patient was added. Patient Name: {patient.Name}", user);
else
auditLog.Write(AuditType.Added, $"Patient was modified. Patient Name: {patient.Name}", user);
}
public void OnDelete(IEntityEntry<Patient> entry, IUnitOfWork unitOfWork)
{
User user = GetCurrentUser();
Patient patient = entry.Entity;
auditLog.Write(AuditType.Deleted, $"Patient was deleted. Patient Name: {patient.Name}", user);
}
...
}
The entity interceptors are nothing more than extension points that the iQuarc Data Access library provide (a simple OCP application). They are somehow similar with database triggers in the sense that we can write code that executes when an entity is saved, loaded or deleted, but it is at a higher level, not in the database. Even more, the code we write does not depend on the EF and it can sit in the Business Logic Layer (DIP application). You can find more details on how they work in my older post or if you just look in the code on GitHub.
There are many other technical features we can easily add in the same way as we did in this example. Here we have implemented a specific interceptor, which executes only for entities of type Patient, but we can also have global interceptors that execute for entities of any type, like in the following example.
Data Audit
Context: We need to set the CreatedBy, LastModifiedBy, CreatedDate and LastModifiedDate columns in most of the tables from the database. We add this feature at a later stage of the project.
To implement this in a generic way for all the entities we need to define an interface. Something like:
public interface IAuditable
{
DateTime? LastModifiedDate { get; set; }
DateTime CreatedDate { get; set; }
string LastModifiedBy { get; set; }
string CreatedBy { get; set; }
}
After we create the correspondent columns in the tables of the database (we can make a T-SQL script that adds them for all tables), the next step is to make all the DTOs, which the ORM maps to the tables, to implement this interface. If we use EF, we can easily modify the code generator to generate the entity classes to implement the interface and the audit columns to be mapped to its properties.
The above needs to be done regardless of the fact that we add this feature at the beging of the project or later. It is almost the same effort / cost.
However, to make sure that we implement this feature in a in a constant manner and these properties are correctly set in all of the Controllers and Services where we modify data, we can again benefit from having an encapsulated data access implementation, which gives us a central place to set this data. Again, by having this, we will not need to go through all the code we've already written, if we are at a later stage of the project.
This time we will make a global interceptor, so it gets executed for all entities types.
[Service("AuditableInterceptor", typeof(IEntityInterceptor))]
public sealed class AuditableInterceptor : GlobalEntityInterceptor<IAuditable>
{
public override void OnSave(IEntityEntryFacade<IAuditable> entity, IRepository repository)
{
var systemDate = DateTime.Now;
var userName = GetUserName();
if (entity.State == EntityEntryStates.Added)
{
entity.Entity.CreationDate = systemDate;
entity.Entity.CreatedBy = userName;
}
entity.Entity.LastEditDate = systemDate;
entity.Entity.LastEditBy = userName;
}
...
}
The data access implementation, finds in the Dependency Injection Container all the implementations of IEntityInterceptor, including the above, and for each entity that was modified, deleted, added or loaded it calls the correspondent functions of each interceptor found. The GlobalEntityInterceptor<T> is just an implementation helper (Template Method design pattern applied), which casts each modified entity to IAuditable and if that succeeds it forwards the call to the specific implementation.
public abstract class GlobalEntityInterceptor<T> : IEntityInterceptor
where T : class
{
public abstract void OnLoad(IEntityEntryFacade<T> entry, IRepository repository);
public abstract void OnSave(IEntityEntryFacade<T> entry, IRepository repository);
public abstract void OnEntityRemoved(IEntityEntryFacade<T> entry, IRepository repository);
void IEntityInterceptor.OnLoad(IEntityEntryFacade entry, IRepository repository)
{
if (entry.Entity is T)
this.OnLoad(entry.Convert<T>(), repository);
}
void IEntityInterceptor.OnSave(IEntityEntryFacade entry, IRepository repository)
{
if (entry.Entity is T)
this.OnSave(entry.Convert<T>(), repository);
}
...
}
Data Localization
Context: Our application is an e-commerce site which is in production. Now, we need to enter the French market, where most of the products we sell have different names in French than in English. Therefore, we need to add data localization.
I have written before about data localization, explaining what it is and how it can be implemented. In this older post I give the starting point of implementing it as part of an encapsulated data access implementation. It fits well the above context. It parses each Linq and then recreates the lambda expression with a join to the translation table. Doing this we will not need to go through all the existent code where Products are read to modify it. Instead we intercept the existent queries and we rewrite them.
public class EfRepository : IRepository
{
...
public IQueryable<T> GetEntities<T>(bool localized = true) where T : class
{
DbSet<T> dbSet = GetContext().Set<T>();
return localized ? new LocalizedQueryable<T>(dbSet, this .cultureProvider) : dbSet;
}
...
}
For more details on how to implement the LocalizedQueryable<T> to rewrite the Linq, you can look into the code of the iQuarc Data Localization library that I presented in the previous post.
Multitenancy
Context: Our application is in a late stage of development, or even deployed in production, and we decide that the same instance of the application should be used by more clients. Therefore, we need to add support for the multitenancy scenario.
There are more strategies to implement a multitenant application. The most common are to have separate databases, one for each client (tenant), or to have one database shared by all clients and use a discriminant column like TenanatID to separate each tenant data. Both these strategies could be implemented later in a project, and having a well encapsulated data access where you can intervene to consistently implement it, makes a huge difference. The rest of the code will need minimum changes, given that you will want the same functionality to all your tenants and that your application was built with scalability in mind.
If you go with multiple databases strategy (one for each tenant), the data access implementation will be the place to decide to which database you will connect to execute the current query or command, based on the tenant of the current user. If you go with one database for all the tenants, the data access will be the place where you can intercept each Linq and rewrite it to append a WHERE condition that filters the data by the TenantID of the tenant to which the current user belongs to.
I will detail in a future post more about multitenancy, what should we consider when we choose a strategy and also give some code snippets on how to implement it taking the benefits of an encapsulated data access implementation.
Authorization on data records
Context: The authorization rules say that users from certain roles can read, modify or delete only certain records of some entities. This means that data in the list screens, for example, needs to be filtered based on the access rights of the current user. We need to add this, at a later stage of the project.
In most of the applications when we implement the authorization (what the current user is allowed to do) we restrict some functionalities for some users. For example a user from the Guest role can only see the list of products. She does not have access to Buy functionality. Only users from the Customer role can buy products. Even more, the Edit Product functionality is only available to users from Sales Manager role.
Authorization on data records goes a step further. It says that a Sales Manager user has access to Edit Product functionality, but she can edit ONLY the products that are at sale in the area managed by that user.
To implement this it means that we need to go in all the screens that show products for edit and filter them by some data from the current user. Going back through all these screens and mix this authorization logic with existent queries might be costly and may result in a hard to maintain code.
However, if we have a well encapsulated data access through which all our queries go, it means that we could intercept them and based on some conventions rewrite the Linq to append a WHERE condition that filters the result by some data from the current user. Again, we can rely on the data access to add this functionality later.
I will detail this more and I'll also give some code snippets on how it could be done, in a future post.
To summarize, we have seen some examples of some extra benefits an encapsulated data access brings. In all theses cases we could add technical functionalities at a later stage of the project with costs that do not depend on how much business functionality was already implemented.
All of the implementations rely on the fact that all the queries and the commands go through a central place: the data access implementation. This means that we can either use some extensibility points like the entity interceptors to execute custom code when data is loaded, modified or deleted; or we could rewrite the Linq to enrich it with the functionality we want. If our data access is implemented with a Linq based framework like EF, the resulted code, even if it may be complex, is testable and maintainable. Even more, this complexity remains separated from the business functionalities, somewhere in the infrastructure of our project, rather than being spread all over the code base.
More about how to implement an encapsulated data access and how to benefit from it is discussed in my Code Design Training
Featured image credit: alinoubigh via 123RF Stock Photo

Why Design Upfront Reduces Cost and Increases Predictability
Skipping design may speed up the start of a project, but it often increases long-term cost, complexity, and delivery risk. Real examples from insurance, energy, and logistics systems show why good Code Design, decomposition, and AI-aware architecture are critical for predictability and efficiency.

Code Design for Predictability: Why You Should Hide the Frameworks
Learn how hiding frameworks behind structured infrastructure improves code design, controls complexity, increases predictability, and creates better guardrails for scalable systems and Agentic AI.

Designing Resilient Software Systems for the Energy Sector
Resilience is the primary requirement for software systems in the energy sector. These systems support critical operations such as grid balancing, energy trading, risk management, and asset management. Failure is not an option. Energy systems must operate continuously. Orders must always be processed. Data loss is unacceptable. Business processes must

How Delivery Architecture Enables Predictable Software Projects
Learn how to design software projects for predictable delivery using Delivery Architecture. Align Code Design, System Design, and Project Design to control complexity, reduce risk, and deliver on time and on budget.

Coding with Copilot on Top of Application Infrastructure
AI coding works best on top of strong Application Infrastructure. With clear structure, strict boundaries, and consistent design rules, Copilot and AI Agents generate cleaner, more predictable code. Architecture guides the AI, not the other way around.

Integration Gateway for External Systems
An Integration Gateway isolates your system from external changes and failures while standardizing communication. This article explores a Code Design approach using Contract-First Design, Pluggable Applications, and Clean Architecture for reliable and maintainable software integration.
Drawing from our extensive project experience, we develop training programs that enhance predictability and reduce the cost of change in software projects.
We focus on building the habits that make developers adopt the industry best practices resulting in a flexible code design.

