Separating Data Access Concern
In our days most of the applications that have a relational database as storage, use an ORM to access the data. The ORM (Entity Framework, Hibernate, etc.) does most of the data access implementation. Many of them have a modern API for querying data and for creating sessions of editing

In our days most of the applications that have a relational database as storage, use an ORM to access the data. The ORM (Entity Framework, Hibernate, etc.) does most of the data access implementation. Many of them have a modern API for querying data and for creating sessions of editing and saving changes. They also provide mechanisms to hook on events of data being loaded or before data is saved.
However, using the ORM API directly into the classes which implement the business logic (and business flows) or into the Controllers (or ViewModels) which have the UI logic is not a good idea in most of the cases. It would lead to low maintainability and high costs of change. The main reasons for this are poor consistency on how the data access is done throughout the entire app and mixture of business logic with data access concerns.
Think that we are going to use EF in the entire application to access the database. In a large code base there will be places where the EF context is created in the constructor of the class that uses it, and there will be places where the context will be created in the method that needs to get or alter some data. In some cases the context will be disposed by the class that created it and in others it will not be disposed at all. There will be cases where it is passed in as a parameter by the caller code because of the entities which are bound to it. There will also be cases where under certain circumstances entities are going to be attached to newly created contexts. Does this sound familiar?
All these signal poor consistency which leads to increased complexity. When we add error handling, logging or multiple contexts for multiple databases the complexity increases exponentially and becomes uncontrollable. Adding features like: data auditing, data localization, instrumentation (for performance measurements) or enhancing the data access capabilities in any other ways, becomes very costly. It implies going through the entire code base where EF context was used and do these changes. When business logic is not well separated from data consistency validations, enhancing data access capabilities will most likely affect the use case functionalities. We’ll introduce bugs. Our code will smell as rigid and fragile.
To avoid all the above, we can abstract the data access and encapsulate its implementation by hiding the EF from the caller code. The caller code will not be able to do data access in any other ways, but the ones defined by our abstraction. The abstraction has to be good enough not to limit the capabilities of the underlying ORM, and to allow the implementation to hide it, without leaking any dependencies to above layers.
In the rest of the post I will detail such an implementation. Its code source is available on iQuarc github account, in the DataAccess repository. It is designed as a reusable component, which can be installed as a NuGet package.
The main goals of this library are:
- to support a consistent development model for reading or modifying data in the entire application
- to enforce separation of concerns by separating data access from business logic
One of the main ideas is that the assemblies that need to do data access (the ones that implement the business logic) are not allowed to have any references to the Entity Framework assemblies. They can only depend and use the public interface exposed by the DataAccess assembly. They will reference things like System.Data or System.Core and will take full advantage of LINQ or IQueryable, but they do not know that EF is behind. As far as they are concerned any ORM that gives a compatible IQueryProvider implementation may be used as implementation of the abstract DataAccess interfaces they use. The figure below illustrates this:
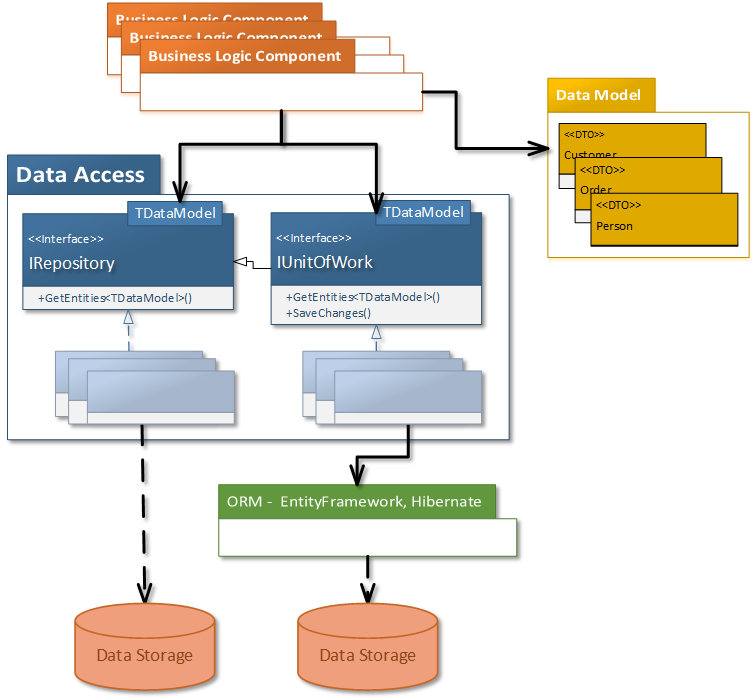
This enforces consistency on how data access is done in the entire application. Any class that needs to access data has to use the DataAccess interfaces, because they can no longer create or get an EF context. Now, each time we need to change or enhance the data access implementation, there is one central place to do this.
Another important aspect revealed by above diagram is that the database model classes are separated into their own assembly (DataModel). Since with the code first support, we can generated simple POCOs, which have no dependencies to the EF, as classes mapped to the database tables. These POCOs remain as simple as they are, and they change only when the database model changes. They will not have logic.
Having this plus the constraint that the DataAccess assembly cannot reference the DataModel assembly we assure that the business logic does not get mixed with the data access concerns. Inside the DataAccess we cannot write any business logic (not even validations), because it does not know about domain entities and in the other assemblies we cannot have data access concerns because they are well encapsulated into the DataAccess assembly.
Now, let’s explore in more detail the code.
IRepository and IUnitOfWork are the main interfaces of the public API the DataAccess library offers. Besides them, there are few more types, but these give the development patterns of doing data access.
IRepository is meant to read data. It is a generic interface that supports queries starting from any entity.
/// <summary>
/// Generic repository contract for database read operations.
/// </summary>
public interface IRepository
{
/// <summary>
/// Gets the entities from the database.
/// </summary>
/// <typeparam name="T">The type of the entities to be retrieved from the database.</typeparam>
/// <returns>A <see cref="IQueryable" /> for the entities from the database.</returns>
IQueryable<T> GetEntities<T>() where T : class;
/// <summary>
/// Creates a new unit of work.
/// </summary>
/// <returns></returns>
IUnitOfWork CreateUnitOfWork();
}
In most of the cases it can be received through dependency injection into the constructor of a class that needs to deal with data. Because its implementation is light (entities are for read only), its scope may be larger and its implementation can be disposed when the operation ends (see my Disposable Instances Series blog posts on how to handle the IDisposable with Dependency Injection).
The examples below, show the code patterns for reading data:
private readonly IRepository rep; // injected w/ Dependency Injection
public IEnumerable<Order> GetAllLargeOrders(int amount)
{
var orders = rep.GetEntities<Order>()
.Where(o => o.OrderLines.Any(ol => ol.Ammount > amount)
return orders.ToList();
}
Queries may be reused and returned to be enhanced or composed by the caller code, in the same operation scope:
private readonly IRepository rep; // injected w/ Dependency Injection
private IQueriable<Order> GetAllLargeOrders(int amount)
{
var orders = rep.GetEntities<Order>()
.Where(o => o.OrderLines.Any(ol => ol.Ammount > amount)
return orders;
}
public IEnumerable<OrderSummary> GetRecentLargeOrders(int amount)
{
int thisYear = DateTime.UtcNow.Year;
var orders = GetAllLargeOrders(amount)
.Where(o.Year == thisYear)
.Select(o => new OrderSummary
return orders;
}
The IUnitOfWork interface is used to modify data.
/// <summary>
/// A unit of work that allows to modify and save entities in the database
/// </summary>
public interface IUnitOfWork : IRepository, IDisposable
{
/// <summary>
/// Saves the changes that were done on the entities on the current unit of work
/// </summary>
void SaveChanges();
/// <summary>
/// Saves the changes that were done on the entities on the current unit of work
/// </summary>
Task SaveChangesAsync();
/// <summary>
/// Adds to the current unit of work a new entity of type T
/// </summary>
/// <typeparam name="T">Entity type</typeparam>
/// <param name="entity">The entity to be added</param>
void Add<T>(T entity) where T : class;
/// <summary>
/// Deletes from the current unit of work an entity of type T
/// </summary>
/// <typeparam name="T">Entity type</typeparam>
/// <param name="entity">The entity to be deleted</param>
void Delete<T>(T entity) where T : class;
/// <summary>
/// Begins a TransactionScope with specified isolation level
/// </summary>
void BeginTransactionScope(SimplifiedIsolationLevel isolationLevel);
}
The pattern here is: read data, modify it and save the changes. These operations should be close one to the other, in a short and well defined scope, like below:
public void ReviewLargeAmountOrders(int amount, ReviewData data)
{
using (IUnitOfWork uof = rep.CreateUnitOfWork())
{
IQueryable<Order> orders = uof.GetEntities<Order>()
.Where(o => o.OrderLines.Any(ol => ol.Ammount > amount);
foreach(var order in orders)
{
order.Status = Status.Reviewed;
order.Cutomer.Name = data.CustomerNameUpdate;
…
}
ReviewEvent re = new ReviewEvent {…}
uof.Add(re)
uof.SaveCanges();
}
}
We want the IUnitOfWork to always be used inside a using statement. To enforce encourage this, we do not register its implementation into the Dependency Injection Container, but we make a factory. The factory may be the IRepository itself. We prefer this, rather than forcing a class, that needs data, to have an extra dependency to an IUnitOfWorkFactory.
Another thing to notice here is that the IUnitOfWork inherits from IRepository. This gives two advantages:
- queries defined for the repository may be reused on an
IUnitOfWorkinstance to get data for changing it - the
IUnitOfWorkinstance may be passed as anIRepositoryparam to code that should only read data in the same editing context
The classes that implement these two interfaces are not part of the public API of the DataAccess. The code from above layers should not use them. To enforce this they may be made internal, which I do when the DataAccess is a project in my VS solution. On the other hand, if it is a reusable library this may be too restrictive and may not work with some Dependency Injection frameworks. Leaving them public requires some development discipline to make sure that they are not newed up in the client code.
Another important part of the public API are the IEntityInterceptorinterfaces. They give the extensibility to run custom logic at specific moments when entities are being loaded, saved or deleted.
/// <summary>
/// Defines a global entity interceptor.
/// Any implementation registered into the Service Locator container with this interface as contract ill be applied to
/// all entities of any type
/// </summary>
public interface IEntityInterceptor
{
/// <summary>
/// Logic to execute after the entity was read from the database
/// </summary>
/// <param name="entry">The entry that was read</param>
/// <param name="repository">A reference to the repository that read this entry. It may be used to ead additional data.</param>
void OnLoad(IEntityEntry entry, IRepository repository);
/// <summary>
/// Logic to execute before the entity is written into the database. This runs in the same transaction ith the Save
/// operation.
/// This applies to Add, Update or Insert operation
/// </summary>
/// <param name="entry">The entity being saved</param>
/// <param name="repository">A reference to the repository that read this entry. It may be used to ead additional data.</param>
void OnSave(IEntityEntry entry, IRepository repository);
/// <summary>
/// Logic to execute before the entity is deleted the database. This runs in the same transaction with he Save
/// operation.
/// </summary>
/// <param name="entry">The entity being deleted</param>
/// <param name="repository">A reference to the repository that read this entry. It may be used to ead additional data.</param>
void OnDelete(IEntityEntry entry, IRepository repository);
}
There are global interceptors, which are triggered for all the entities of any type and there are specific entity interceptors, which are triggered for the all entities of one specific type. Interceptors are a good candidate to implement data consistency validations or data auditing. Their implementations belong to above layers and are a key element for keeping business logic outside of the data access assembly.
Another element to mention is the custom exception classes. To prevent breaking encapsulation at error handing, the DataAccess implementation wraps all the EF exceptions, for the errors that need to be passed to the client code, into custom exceptions that are defined. It abstracts the errors and lets the client code to do the error handing without depending on EF specifics.
You can explore further the DataAcess code on its GitHub repository. To see more examples on how it is used, you can look over the sample from my Code Design training, which are also available as a GitHub repository.
This implementation is discussed in detail in my Code Design Training
Featured image credit: kirillm via 123RF Stock Photo

Why Design Upfront Reduces Cost and Increases Predictability
Skipping design may speed up the start of a project, but it often increases long-term cost, complexity, and delivery risk. Real examples from insurance, energy, and logistics systems show why good Code Design, decomposition, and AI-aware architecture are critical for predictability and efficiency.

Code Design for Predictability: Why You Should Hide the Frameworks
Learn how hiding frameworks behind structured infrastructure improves code design, controls complexity, increases predictability, and creates better guardrails for scalable systems and Agentic AI.

Designing Resilient Software Systems for the Energy Sector
Resilience is the primary requirement for software systems in the energy sector. These systems support critical operations such as grid balancing, energy trading, risk management, and asset management. Failure is not an option. Energy systems must operate continuously. Orders must always be processed. Data loss is unacceptable. Business processes must

How Delivery Architecture Enables Predictable Software Projects
Learn how to design software projects for predictable delivery using Delivery Architecture. Align Code Design, System Design, and Project Design to control complexity, reduce risk, and deliver on time and on budget.

Coding with Copilot on Top of Application Infrastructure
AI coding works best on top of strong Application Infrastructure. With clear structure, strict boundaries, and consistent design rules, Copilot and AI Agents generate cleaner, more predictable code. Architecture guides the AI, not the other way around.

Integration Gateway for External Systems
An Integration Gateway isolates your system from external changes and failures while standardizing communication. This article explores a Code Design approach using Contract-First Design, Pluggable Applications, and Clean Architecture for reliable and maintainable software integration.
Drawing from our extensive project experience, we develop training programs that enhance predictability and reduce the cost of change in software projects.
We focus on building the habits that make developers adopt the industry best practices resulting in a flexible code design.

