Decide between In-Process or Inter-Process Communication at Deploy Time
After a long vacation in October last year, followed by some intensive work at MIRA and InfiniSwiss, now I can make some time to share some more design ideas that I have implemented along the years. I thought to resume blogging with showing how we could design for something which

After a long vacation in October last year, followed by some intensive work at MIRA and InfiniSwiss, now I can make some time to share some more design ideas that I have implemented along the years.
I thought to resume blogging with showing how we could design for something which sounds quite amazing:
Without changing any code nor any configuration file, without recompiling, just by copying binaries on the same or on different servers, we can change how same two classes communicate: in the same process or inter-process communication.
In other words, at Deploy Time we can decide if the same two classes communicate through simple function calls (in-process communication) or through an inter-process communication protocol (like
HTTP), without recompiling nor changing anything else.
I presented this last year at some conferences and I got very good feedback, so I think it worth a few posts.
A good example where this design brings an important advantage is a financial system. Here performance is critical and at the same time it deals with large loads (in data and transactions), so it needs to scale well. With this technique we can decompose the system in more micro-services. This assures a good scalability, each of the micro-service may be deployed more times on more servers. Then, after we get some metrics from running it in production, if we see that two services have a very intensive communication and the inter-process communication affects the performance, we may redeploy those two services on the same server, load them in the same process and have them communicate directly without any overhead. And, we can do all these without changing any code, without recompile.
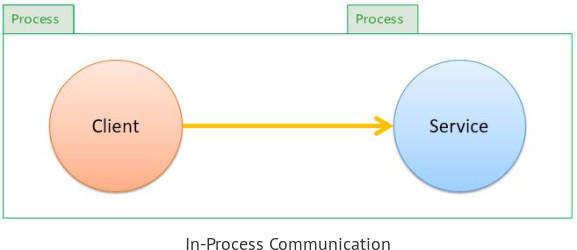
To explain it, we can simplify everything to the communication between a Client and a Service. If they are hosted in the same process as shown below they communicate through function calls as we'd expect
Then, if we deploy the same two classes on different servers (different processes), without changes or recompilation they will do an inter-process communication.
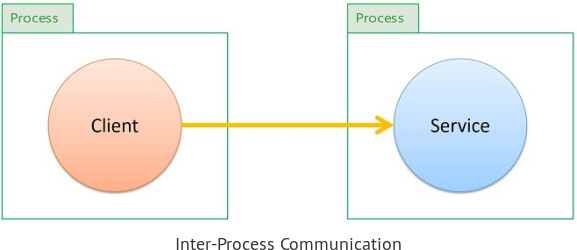
This may be useful in any Enterprise Architecture, because we could scale out, or on the contrary we could bring more components on the same box, without changing code. If we don't change code we have no risks of breaking things, so we don't need extensive regression testing. Even more, we don't need to bother the development team for this deployment optimization. This flexibility that we gain at Deployment Time, may be very cost effective.
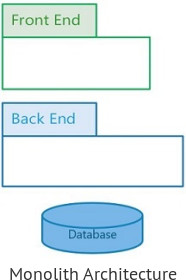
The first time I've implemented this design was with a client that came after a migration from a Monolith Architecture like below (one big Windows Service for the backend on top of a database and one fat client),
to a Distributed Architecture, which had more sub-systems that composed the backend, more databases, a Service Bus for orchestrating the communication and different clients offering the user interface. A modern architecture.
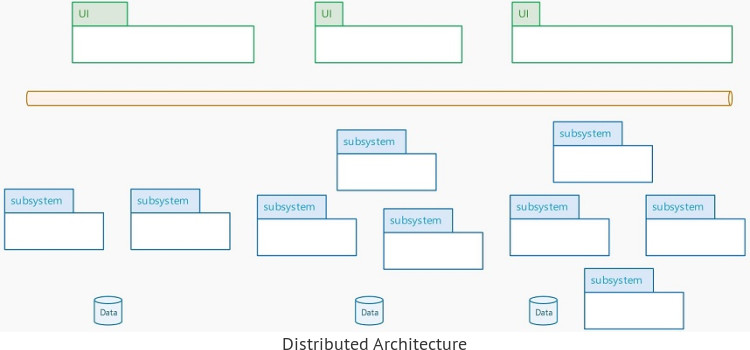
With this architecture they got many benefits in implementing scalability, availability, reliability and even better security. More important for them were the benefits in the maintainability and testability. They moved from one big thing to more and smaller things. Each of the resulted sub-system was now developed, changed and tested on its own, in isolation. They were able to reach one release per month from one release per year which they had with the monolith.
However, all these came with a major drawback: performance problems due to communication overhead. They had cases in which to satisfy a business flow, say Place Order, they had like a dozen service call hops in the backed to complete it and give the response to the user. The overhead with serialize the request, place it on the wire to send it to the service provider, which has to deserialize it, and then serialize the response and place it on the wire back to the client, was significant. And this had to be done for each call, within that business request. They split the monolith, but they were having performance problems due to the communication between the resulted pieces.
One could argue that the decomposition wasn't right. And probably that was the case, but in a large enterprise system it is very hard to get it right from the start. Every refactoring, migration and new feature has to be added gradually so you can continuously perform and deliver business value. So they couldn't redo the composition all at once. Another idea was to merge back some sub-systems, but they would loose the benefits they've gained in maintainability, testability and frequent releases and they were risking to go back to a monolith.
So in this context a design that takes the best from both cases was the solution.
We wanted to:
- continue to develop, test and maintain each sub-subsystem in isolation, as if it was hosted individually in its own process, and
- be able to load more sub-subsystem in the same process and have them communicate through simple function calls, to
- be able to think about the decomposition of the system regardless of the deployment and communication concerns (primary focus on volatility and sources of change, rather than communication when making the decomposition)
- decide only at Deploy Time (configuration only), which sub-subsystem are loaded in the same process to communicate directly and which are loaded on different servers to scale and have inter-process communication between them
There are three key design ideas to achieve all these:
- Depend only on Contracts, which are expressed by abstract types (interfaces). This means that:
- the contracts between the sub-systems are written as interfaces, DTOs and Exceptions only
- they do not contain logic
- they are the only types that have business knowledge and are shared (referenced by) all the sub-systems
- there are no references (hard dependencies) among the sub-systems implementations nor binaries
- Use Proxies to forward the call to a contract to the actual implementation. The communication between a client and a service will be materialized through proxies. By convention:
- if the implementation is available in the same process, a proxy that forwards the call in the same process will be used
- if the implementation is not available in the same process, a proxy that can forward the call through a inter-process communication protocol (
HTTP) will be used
- Use Type Discovery to determine what implementations were deployed on each process
- at startup each process will discover (with reflection or other similar means) the implementations deployed and their dependencies
- based on conventions it will configure the Dependency Injection container on what proxies to use as implementation for the contracts that are implemented by other sub-systems
In the next posts we'll take a simple example with some classes that depend one on the other and we'll demo how this design can be implemented to achieve all the benefits outlined here. The demo will start from a high level overview and will go deep into code until we'll get to a runnable solution, in which just by copying binaries from one output folder to another we'll change the way communication happens.
To implement this I use the iQuarc.AppBoot. It offers all the features needed to implement such a design in C#/.NET. I wrote about it in my last post. The demo will be in C#/.NET, but the same ideas could be applied in other technologies. You just need some form of Dependency Injection and Reflection.
By attending my Code Design Training you will learn how to implement this design idea in your context, to maximize the benefits for your requirements
Featured image credit: bluebay via 123RF Stock Photo

Why Design Upfront Reduces Cost and Increases Predictability
Skipping design may speed up the start of a project, but it often increases long-term cost, complexity, and delivery risk. Real examples from insurance, energy, and logistics systems show why good Code Design, decomposition, and AI-aware architecture are critical for predictability and efficiency.

Code Design for Predictability: Why You Should Hide the Frameworks
Learn how hiding frameworks behind structured infrastructure improves code design, controls complexity, increases predictability, and creates better guardrails for scalable systems and Agentic AI.

Designing Resilient Software Systems for the Energy Sector
Resilience is the primary requirement for software systems in the energy sector. These systems support critical operations such as grid balancing, energy trading, risk management, and asset management. Failure is not an option. Energy systems must operate continuously. Orders must always be processed. Data loss is unacceptable. Business processes must

How Delivery Architecture Enables Predictable Software Projects
Learn how to design software projects for predictable delivery using Delivery Architecture. Align Code Design, System Design, and Project Design to control complexity, reduce risk, and deliver on time and on budget.

Coding with Copilot on Top of Application Infrastructure
AI coding works best on top of strong Application Infrastructure. With clear structure, strict boundaries, and consistent design rules, Copilot and AI Agents generate cleaner, more predictable code. Architecture guides the AI, not the other way around.

Integration Gateway for External Systems
An Integration Gateway isolates your system from external changes and failures while standardizing communication. This article explores a Code Design approach using Contract-First Design, Pluggable Applications, and Clean Architecture for reliable and maintainable software integration.
Drawing from our extensive project experience, we develop training programs that enhance predictability and reduce the cost of change in software projects.
We focus on building the habits that make developers adopt the industry best practices resulting in a flexible code design.

